
为了应对大模子连续庞杂的推理和磨练,英伟达、AMD、英特尔、谷歌、微软、Meta、Arm、高通、MatX以及Lemurian Labs,纷纷开头研发全新的硬件办理计划。
放眼一看,宇宙把完全的⽬光都聚焦正在数字款式上。由于正在过去的⼗年中,AI硬件服从的提⾼有很⼤⼀个别要归功于数字款式。
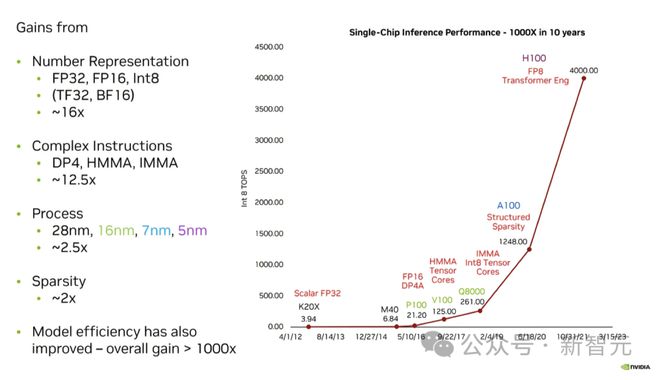
英伟达声称,过去10年,单芯⽚TOPS晋升了足足1000倍,英伟达自己就加起来达16倍。相⽐之下,从28nm到5nm,⼯艺本领的改革仅为2。5倍!
Semianalysis的最新作品中,从数字款式的根本道理起程,深⼊斟酌了神经⽹络量化的本领近况。
本⽂中,将先容浮点与整数、电道安排戒备事项、块浮点、MSFP、微缩款式、对数体例等实质,还会先容量化和推理数字款式的差别,以及⾼精度与低精度磨练伎俩。

末了,文中将先容英伟达、AMD、英特尔、谷歌、微软、Meta、Arm、高通、 MatX和Lemurian Labs等硬件开拓商正在扩展⽬前流⾏的8位款式(如FP8和Int8) 时将采⽤的本领。
正在GPT-3中,每⼀层都要进⾏⼤量的矩阵乘法运算:比方,此中⼀个完全运算是⼀个(2048 x 12288)矩阵乘以⼀个(12288 x 49152)矩阵,然后输出⼀个(2048 x 49152)矩阵。
紧张的是若何盘算输出矩阵中的每个元素,这可能归结为两个⾮常⼤的向量的点积(正在上⾯的例⼦中,⼤⼩为12288)。
这席卷12288次乘法和12277次加法,累积成⼀个数字,即输出矩阵的单个元素。
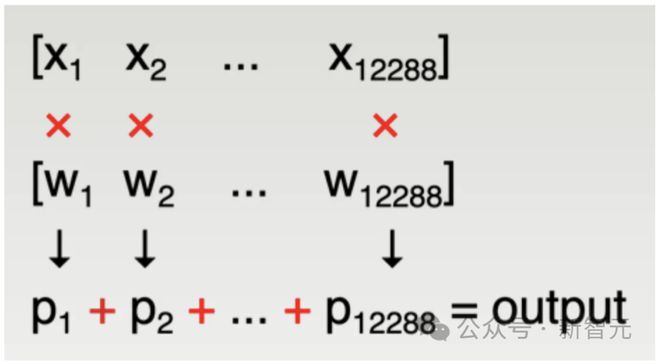
每个周期的模糊量均为1,原委~12288个周期后,输出矩阵的单个元素的累加达成。
这种「协调乘加」运算(FMA)是机械进修的根本盘算单位:芯⽚上成千上万个FMA单位原委计谋性分列,可⾼效地反复使⽤数据,从⽽并⾏盘算输出矩阵的很众元素,从而节减所需的周期数。
1。 杀青优越的能量和⾯积服从。这苛重取决于权重和激活所使⽤的数字款式。
2。 既要⾜够准确地存储数千亿个权重,又要使⽤尽不妨少的位,以便从容量和带宽的角度节减内存占⽤。这取决于⽤于存储权重的数字款式。
固然H100正在论文中可能杀青2,000 TFLOPS的盘算能⼒,但正在此之前就会遭遇功耗控制,以是每焦⽿能量的FLOPs是⼀个极其紧张的跟踪目标。
鉴于现正在的磨练运⾏每每抢先1e25 FLOP,咱们需求极其⾼效的芯⽚,正在数⽉内损耗兆⽡级的电⼒,以击败SOTA。
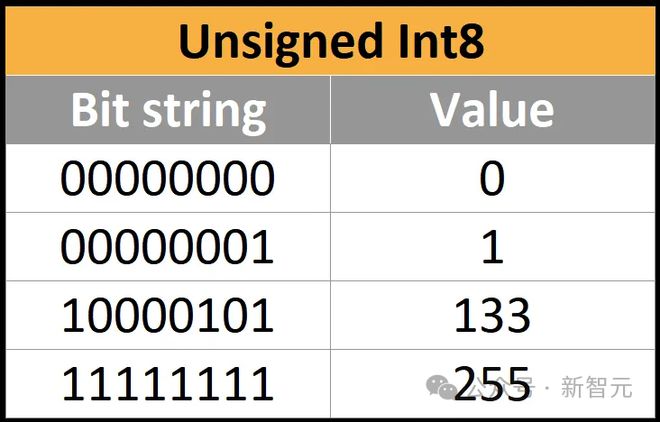
正整数可能用2进制(基数为2)来自然外现。这种外现法称为UINT,即⽆符号整数。下⾯是⼀些8位⽆符号整数的例⼦,也称为UINT8,从0到255。
这些整数的位数不限,但平常只⽀持以下四种款式:UINT8、UINT16、UINT32和UINT64。
负整数需求⼀个符号来划分正负,只需正在最明显位加上⼀个符号即可:比方, 0011外现+3,1011外现-3。这称为符号-数值外现。
下⾯是INT8的⼀些示例,INT8从-128到127。请戒备,因为第⼀位是符号,最⼤值本质上减半了,从255到127。
符号巨细是直观的,但服从很低——你的电道务必杀青相当差异的加法和减法算法,⽽这些算法又与⽆符号整数的电道差异。
风趣的是,硬件安排⼈员可能通过使⽤⼆进制外现法来办理这个题目,云云就可能对正数、负数和⽆符号数使⽤完整沟通的进位阶梯电道。完全新颖CPU都使⽤⼆进制外⽰法。
为了让INT8和UINT8共享硬件资源,可能⽤1111111111来外⽰-1。现正在,当数字1相加时,会溢出到00000000,如预期的那样外现0。同样,11111110也可能外⽰为-2。
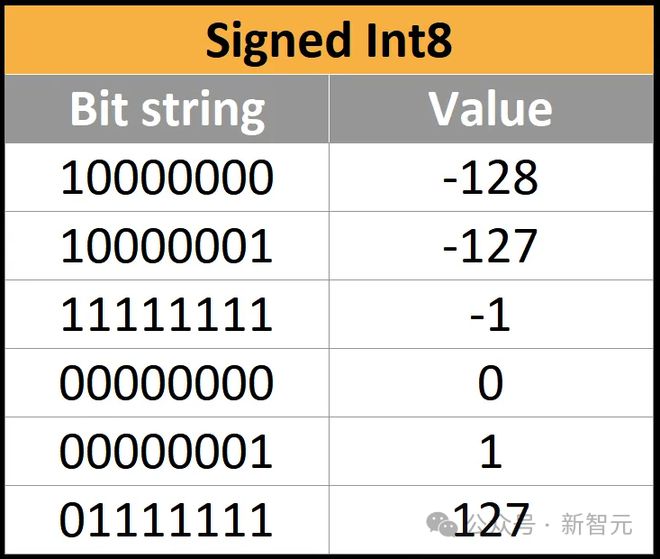
溢出是一种特点!本质上,0到127被照射为平常值,128到255被直接照射到-128到-1。
固然这些都是整数,但你也可能联思它们是其他数的倍数!比方,0。025即是千分之25,可能直接存储为整数25。现正在,咱们只需正在其他地⽅记住宅有正正在使⽤的数字都是千分之⼀。
新的「数字款式」可能⽤千分之⼀来外现-0。128到0。127的数字,本质逻辑没有转移。整数仍被视为整数,然后⼩数点被固定正在右起第三个地位。这种计谋称为定点法。
⼀般来说,这是⼀个有⽤的计谋,本⽂中会每每提到——要是你思改造可能外现的数字规模,可能正在某个地⽅增加⼀个⽐例因⼦。(很清楚,你可能正在⼆进制中云云做,但⼗进制更容易辩论)。
但是,定点也有⼀些漏洞,越发是乘法运算。⽐⽅说,你需求盘算1万亿乘以1万亿分之⼀。
⼤⼩上的巨⼤差别即是⾼「动态规模」的⼀个例⼦。那么10^12和10^-12都务必⽤数字款式来外现,以是很容易盘算出需求众少位:从0到1万亿,以1万亿为增量,需求10^24的增量,log2(10^24)~= 80 位,智力以咱们思要的精度外现动态规模。
每个数字是80位较着口舌常蹧跶的。你不⼀定闭⼼绝对精度,你需求闭⼼的是相对精度。
以是,尽管上述款式可以精确划分1万亿和999,999,999,999。9999999999之间的偏差(⼀般也不需求划分)。⼤众半景况下,你闭⼼的是相对待数字⼤⼩的偏差量。
这恰是科学记数法所要办理的题目:正在前⾯的例⼦中,咱们可能将⼀万亿写成1。00 * 10^12,将⼀万亿分之⼀写成 1。00 * 10^-12,云云存储量就⼩得众了。
云云固然更庞杂,但可能让你正在沟通的上下⽂中毫⽆顾虑地外现极⼤和极⼩的数字。
以是,除了符号和数值外,咱们现正在另有⼀个指数。IEEE 754-1985正在当时使⽤的很众略有差异的⼆进制款式中,法式化了业界通⽤的⼆进制存储⽅式。
苛重的风趣款式——32位浮点数(float32或FP32)可能描写为 (1,8,23):1个符号位、8个指数位和23个尾数位。
- 指数位被解说为⽆符号整数e,代外⽐例因⼦2^e-127,其代价介于2^-126和2^127。更众的指数位意味着更⼤的动态规模。
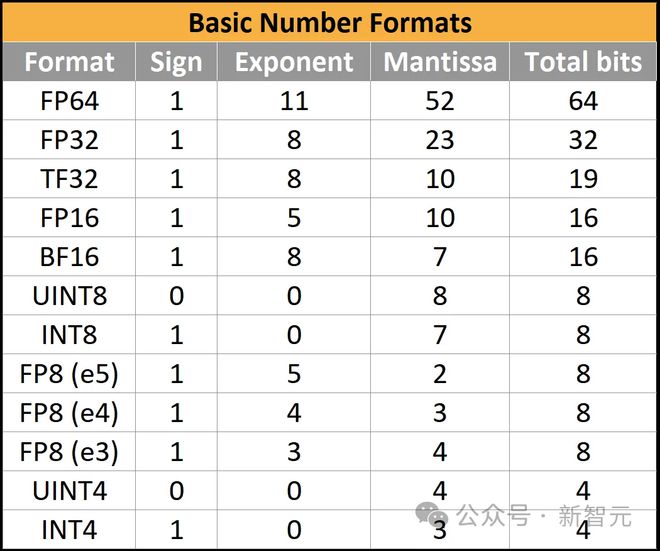
其他位宽已被法式化或显示采⽤,比方FP16(1,5,10)和BF16(1,8,7)。而争吵的主旨正在于规模与精度。
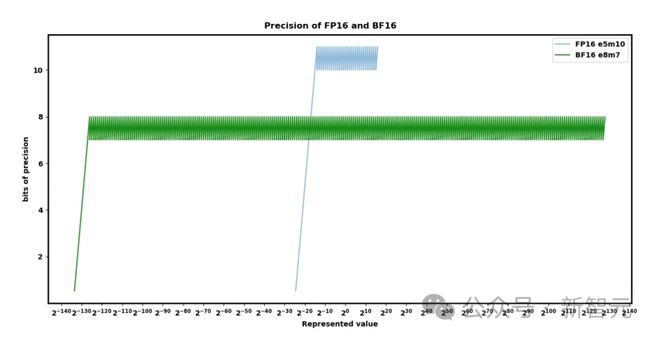
FP8(1,5,2或1,4,3)近来正在OCP法式中法式化了极少非常的奇特轨则,但目前还没有定论。很众人工智能硬件公司依然杀青了具有稍微卓绝的变体的芯片,但这些变体与法式不兼容。
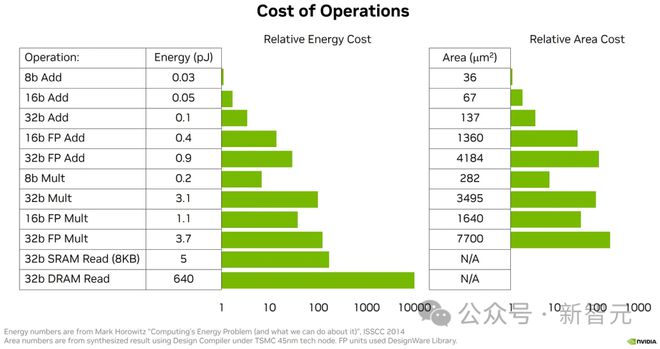
固然加法器的本质杀青要庞杂得众,但有⼀种⽅法可能让咱们把加法器联思成⼀道加法并依据需求带领1,以是从某种旨趣上说,⼀个n位加法器所做的⼯作量与n成正⽐。
闭于乘法,回思⼀下⼩学的长乘法。咱们进⾏n位数乘以1位数的乘积,末了将完全结果相加。
正在⼆进制中,乘以⼀位数是微不⾜道的(0或1)。这意味着n位乘法器骨子上是n位加法器的n次反复,以是⼯作量与n^2成正⽐。
固然本质应⽤因⾯积、功耗和频率控制⽽⼤不沟通,但⼀般来说:1)乘法器⽐加法器腾贵得众;2)正在低位数(8位及以下)景况下,FMA的功耗和⾯积本钱相对待加法器的进献越来越⼤(n对n^2缩放)。
- ⾸先,求指数的差值。(假设exp1⾄少和exp2⼀样⼤,要是不⼀样⼤,则正在指令中进⾏交流)
- 正在每个尾数中加⼊⼀个隐含的前导1。要是⼀个符号是负数,则对此中⼀个尾数进⾏2的补码运算。
值得戒备的是,浮点乘法甚⾄可能⽐整数乘法本钱更少,由于尾数乘积中的位数更少,⽽指数的加法器⽐乘法器⼩得众,⼏乎没相闭系。
较着,这也是原委特别简化的,独特口舌典范和nan管理,咱们还没有深⼊商量,这占⽤了⼤量⾯积。但咱们可能得出云云的结论:正在低位数浮点运算中,乘积本钱很低, ⽽累加是腾贵的。
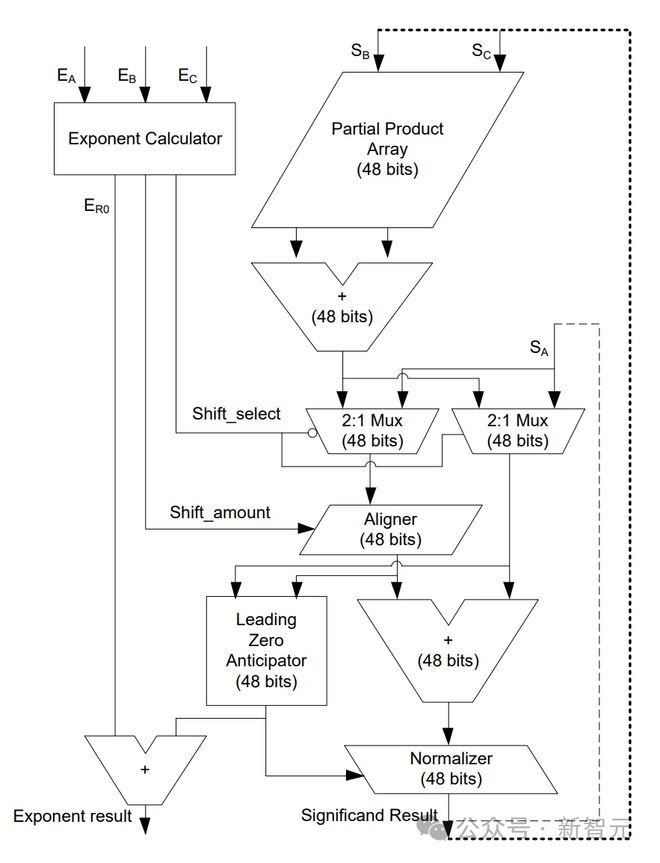
正在这⾥,咱们提到的完全个别都⾮常清楚——将指数相加,尾数的大型乘法器数组,依据需求转移和对齐事物,然后举行归一化劳苦(从本领上讲,真正的「协调」乘法加法有点差异,但正在这⾥省略了)。
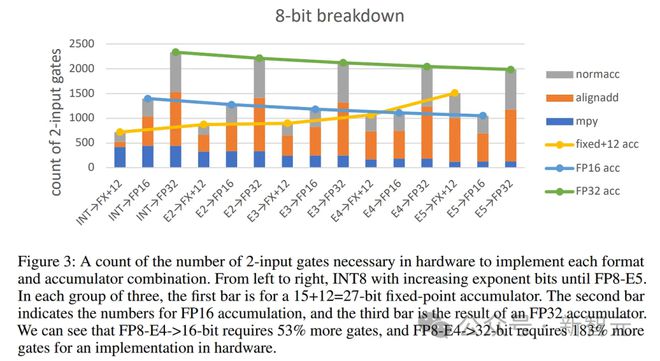
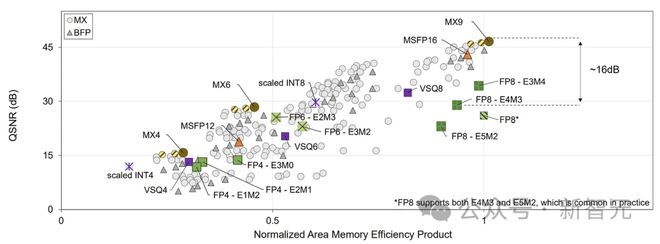
本图外证明了上述完全重点。需求消化的东西许众,但重点是,INT8xINT8累加和累加到定点(FX)的本钱是最省钱的,而且是由乘法(mby)主导,⽽使⽤浮点的操作数或累加款式(平常是巨⼤的)苛重是累加的本钱(alignadd +normacc)。比方,使⽤FP8操作数和「定点」累加器,⽽不是平常的FP32,就可能节约许众本钱。
总⽽⾔之,高通论⽂和其他论⽂称,FP8 FMA⽐INT8 FMA众占⽤40-50%的芯⽚⾯积,能耗同样更⾼,甚⾄更糟。这也是⼤众半专⽤ML推理芯⽚使⽤INT8的苛重道理。
既然整数本钱更低,为什么咱们不去众数使⽤INT8和INT16,⽽要⽤FP8和FP16呢?这要看这些款式能正在众⼤水准上精确地外现神经⽹络中本质显示的数字。
咱们可能把每种数字款式看作⼀个查找外。比方,⼀个2位数字款式不妨是云云的:
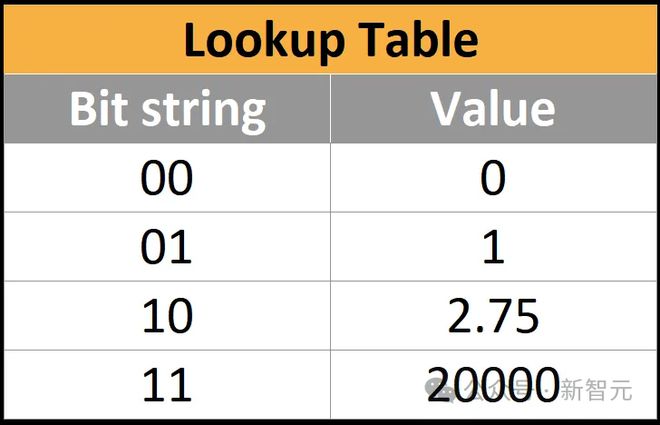
较着,这组四个数字并没有什么⽤处,由于它缺乏了太众半字。毕竟上,基本就没有负数。要是你的神经⽹络中的某个数字不存正在于外格中,那么你能做的即是把它四舍五⼊到最亲切的条⽬,这就给神经⽹络带来⼀点偏差。
例如,要是神经⽹络中的⼤个别数值都亲切0(本质景况也是云云),咱们就期望能有许众数值亲切0,云云咱们就能正在紧张的地⽅得到更⾼的精度,⽽正在不紧张的地⽅亏损精度。
正在实习中,神经⽹络平常是正态分散或拉普拉斯分散(laplace distributed),有时会显示⼤量离群值,这取决于模子组织的完全数值。独特是正在超⼤语⾔模子中,往往会显示尽头离群值,这些 离群值固然罕睹,但对模子的效用⾮常紧张。
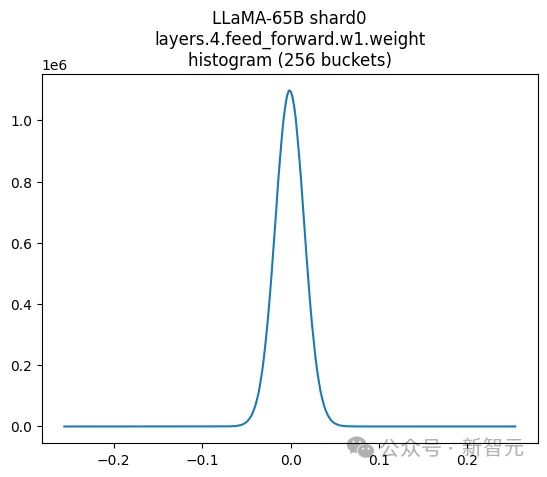
上图显⽰了LLAMA-65B个别的权重,这看起来很像正态分散。要是将其与FP8和INT8中数字的分散进⾏⽐较,就会发掘浮点运算的重心⾮常清楚——亲切于0。这即是咱们使⽤浮点运算的道理!
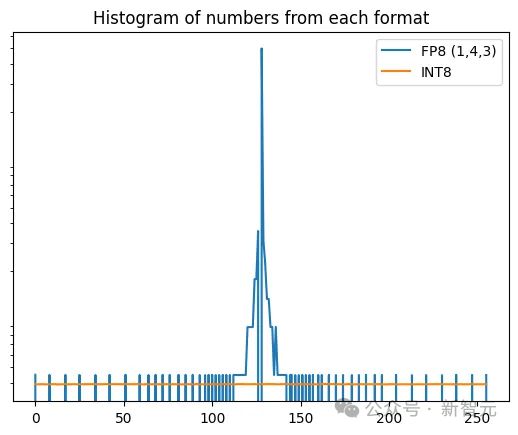
但是,它与的确分散的成家度仍旧不⾼,每次指数递增时城市显示犀利点,但⽐int8好得众。
咱们能做得更好吗?从0开头安排款式的⼀种⽅法是尽量节减均匀绝对偏差,即四舍五⼊变成的均匀牺牲。
比方,英伟达正在HotChips⼤会上提出对数体例是不停扩展8位数字款式的不妨途径。
要了然,对数体例的四舍五⼊偏差⼀般较⼩,但也存正在⼀些题目,席卷加法器的本钱⾼得惊⼈。
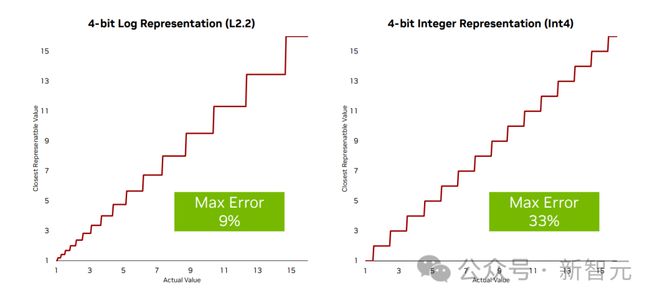
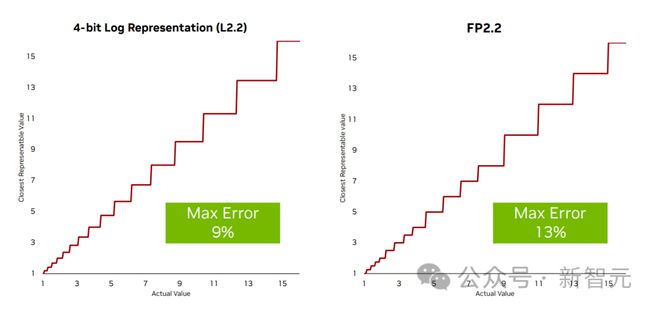
NF4及其变体(AF4)是⼀种4位款式,使⽤准确查找外来最⼩化偏差,假定权重根据完整正态分散。但这种⽅法正在⾯积和功耗上都⾮常昂贵——现正在每次操作都需求查找⼀个庞⼤的条⽬外,这⽐任何INT/FP操作都要倒霉得众。
⽬前有很众替换款式:posits、ELMA、PAL等。这些款式声称正在盘算服从或外述精确性⽅⾯有种种上风,但都还没有到达贸易闭联的界限。
也许此中的⼀种,或者⼀种尚未公告/发掘的,将具有INT的本钱和FP的外征精确性——目前有⼏种依然提出了这⼀主 张,甚⾄更好。
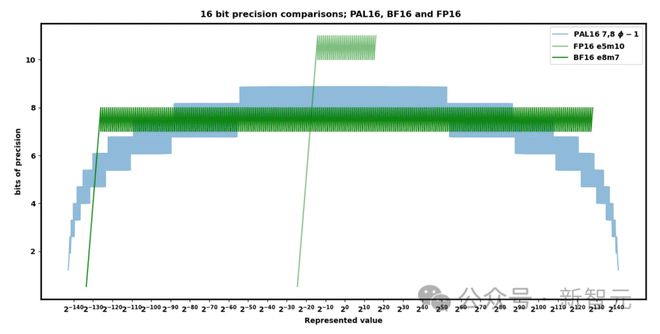
这篇作品的作家对Lemurian Labs PAL抱有很⼤期望,但他们的数字款式另有许众未披露之处。他们声称⾃⼰的16位精度和规模都优于FP16和BF16,同时硬件本钱也更低。
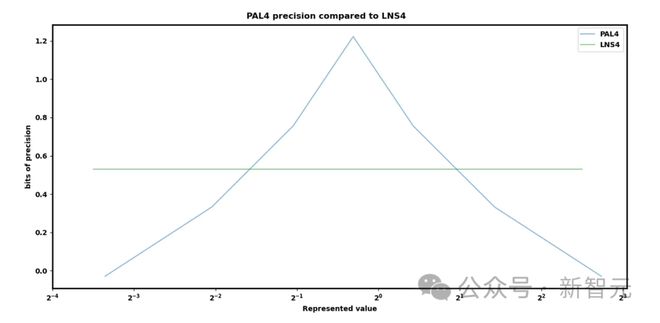
跟着连续扩展8位款式,PAL4还声称其分散⽐英伟达正在HotChips上提出的对数体例更好。他们的论文声明令⼈感叹,但⽬前还没有硬件杀青这种款式。。。。。。。
⼀个风趣的景象是,张量中的元素⼏乎老是与邻近的元素⼤⼩宛如。当张量中的元素⽐平常景况下⼤许众时,邻近的元素根本上就不紧张了——它们相对来说太⼩,无法正在点积中看到。
咱们可能利⽤这⼀点——可能正在众个元素之间共享⼀个指数,⽽不是正在每个数字上都有⼀个浮点指数。云云可能节约⼤量冗余指数。
正在这⼀点上,存正在着⼀整套差异衡量的不妨款式。微软曾试图量化硬件的安排空间:
硬件供应商⾯临着⼀个棘⼿的题目,即既要安排⾼度专业化的⾼效款式,又要不影响改日模子架构的起色,由于改日的模子架构不妨会有迥然不同的数值分散。
推理进程对本钱和功耗独特敏锐,由于一个模子固然只磨练一次,却要效劳于数以百万计的用户。
以是,推理用的芯片会更目标于采用更经济、体积更小的数值款式。而这很不妨会导致,模子正在磨练时应用的款式与推理中应用的差别广大。
正在伎俩谱系的一端,磨练后量化(Post-Training Quantization, PTQ)可能仅通过极少单纯的算法来更新模子的权重,而无需实施任何本质的磨练环节:
- Smoothquant采用一种数学上等价的变换伎俩,来节减卓殊的激活值
- AdaRound将每一层的权重四舍五入的进程视为一个二次二元优化题目,举行独立优化
然而,这种伎俩固然极大地节减了本钱,但本质带来的职能牺牲要比传播的大得众。
正在另一端,量化感知磨练(Quantization-Aware Training, QAT)通过安排模子的精度,并不停磨练一段时分来符合新的精度。
这种体例直会接诈欺旧例的磨练流程让模子符合量化后的形态,后果更好但相应的盘算本钱也更高。
通盘进程中席卷了三次矩阵乘法操作:一次发作正在前向撒布,此外两次发作正在反向撒布中。
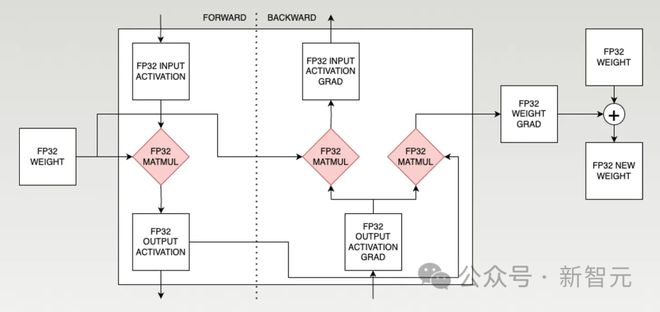
正在每个磨练环节中,体例会接受今朝的权重值,然后通过与差异数据举行一系列矩阵乘法盘算,最终产出更新后的权重值。
FP8款式的磨练流程则愈加庞杂。下面英伟达提出的FP8磨练流程的一个简化版:
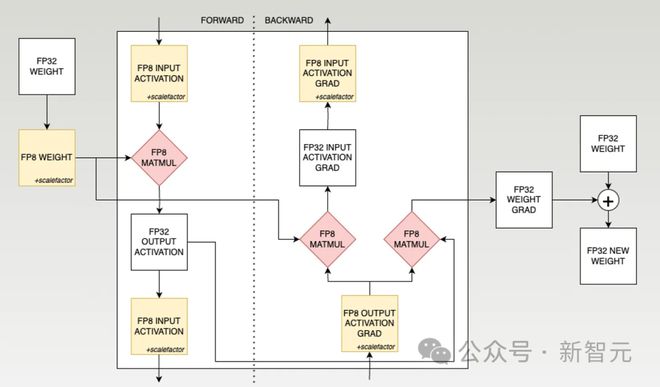
- 进程中的每次矩阵乘法盘算都以FP8 x FP8款式举行,并将结果累积到更高精度的FP32中。之后,为了举行下一层的盘算,这个结果会被量化回FP8款式。之因此需求更高精度来举行累积,是由于它包罗了成千上万次的小幅度更新,这些细微的转移需求足够的精度智力确保不会被渺视掉。
- 每个FP8款式的权重张量都有一个比例因子。鉴于每一层搜集的数据规模不妨迥然不同,安排数据来符合每一层的特定例模非凡症结。
- 正在苛重盘算流程除外,权重更新对精度的央浼也是极高的,平常需求仍旧正在如FP32云云更高的精度水准。这是由于权重的细微更新与原有权重值比拟,数目级差别广大,以是需求足够的精度来确保这些小的更新不会由于四舍五入而消散不睹。
末了,磨练和推理的一个明显区别正在于,磨练进程中的梯度值会显示愈加尽头的卓殊点,这一点非凡症结。
固然可能将激活函数的梯气量化为INT8款式(比方应用SwitchBack或AQT本领),但权重梯度至今仍难以举行云云的量化,以是它务必仍旧正在FP16或者是独特款式的 FP8(1,5,2)中。
正在量化本领这一界限,无论是HuggingFace的模子量化用具,仍旧硬件供应商们,都正在为了杀青更低的比特数、更高的精确率和更好的能效而不懈全力。
然而,这个题目远不止比特数那么单纯——硬件中蕴藏着极大的庞杂性,涉及到众种差异的款式,而这些都有待进一步的优化。
为了跟上黄氏定律(Huangs Law),硬件供应商们也正正在踊跃反映这一挑衅。
最初,Lemurian Labs正埋头于开拓他们自有的特有数字款式。另一家始创公司MatX则将int4数据类型动作他们的中央目的。这两家公司的倾向与其他供应商天差地别。当然,谷歌也正在开垦我方的道道。
至于英伟达、AMD、英特尔、微软、Meta、Arm和高通,则都正在聚焦于Microscaling(MX)款式的开拓。
然而,即使存正在一个联合的法式,也有很众可安排的参数——不但块巨细可能依据需求筑设,数据类型的遴选也同样灵动。
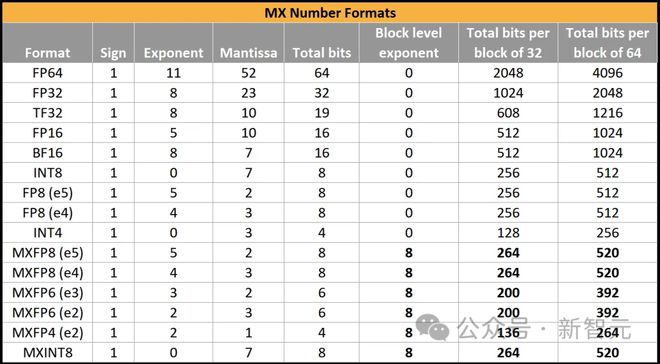
得益于8位指数的块级编码,微缩(microscaling)款式比守旧的FP16浮点款式能外现更宽的数值规模。
即使是精度最高、数值规模最小的MXINT8,其外树模围也抢先了FP16,况且正在32或64位块巨细的景况下,所需的数据位数大约惟有FP16的一半。
风趣的是,微软固然是这些款式的商量和法式化做事的领头羊,却没有遴选扶助MXINT8。据认识,他们正在Braga只扶助MXFP4、FXFP6和MXFP8这几种款式。
Meta规划正在他们与Andes联合安排的CPU中央中扶助微缩款式,这些中央将运用于他们自研的加快器中。AMD和英伟达也正在不遗余力地扶助这些新款式,并将其运用于下一代GPU中。
正在DDR和HBM中,最小的子通道数据传输单元是32位,而正在LPDDR中,这个单元是16位。这就导致了OCP微缩放款式正在数据传输时会显示不常睹的巨细。
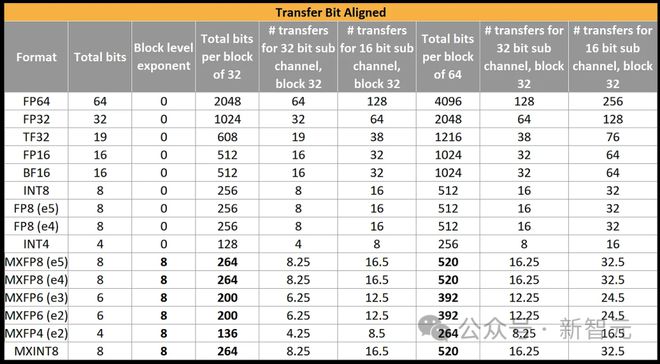
对待FP16和BF16,它们通过16、32或64位的子通道来传输数据,并以此来读取或写入32或64个数值。
然而,当DRAM按16或32位的增量举行数据传输,而需求传输32或64个微缩款式数值的数据块时,就务必传输相当于数据块指数的四分之一或一半。
这意味着,要么牺牲个别外面内存带宽,要么就务必以128为一组举行传输。编译器和底方针序员正在直接为种种加快器编程时,需求思虑这一点。
比拟之下,谷歌确定不根据这一法式,而是为其改日的TPU斥地我方的起色道道。